用 R 核对两个数据差异
楚新元 / 2024-06-21
财务工作者可能经常需要核对报表,这里推荐两个 R 包。
waldo:方便地比较两个 R 对象之间的差异。
diffviewer :提供了一个 HTML 组件,用于直观地比较两个数据文件的差异。
比较两个数据框
其实能比较的对象不止数据框,因为平时工作中用到的数据框的情况比较多,所以这里以数据框为例。
生成示例数据框
# 加载相关 R 包
library(waldo)
library(kableExtra)
# 示例数据
df1 = data.frame(x = c("a", "b", "c"), y = c(1, 2, 5))
df2 = data.frame(x = c("a", "d", "b"), y = c(1, 7, 2))
# 查看这两个数据框
df1 %>%
cbind(df2) %>%
kable() %>%
kable_styling(full_width = TRUE) %>%
row_spec(0:3, align = "center") %>%
add_header_above(c("df1" = 2, "df2" = 2))
| x | y | x | y |
|---|---|---|---|
| a | 1 | a | 1 |
| b | 2 | d | 7 |
| c | 5 | b | 2 |
比较两个数据框的差异
compare(df1, df2)
#> old vs new
#> x y
#> old[1, ] a 1
#> - old[2, ] b 2
#> + new[2, ] d 7
#> - old[3, ] c 5
#> + new[3, ] b 2
#>
#> `old$x`: "a" "b" "c"
#> `new$x`: "a" "d" "b"
#>
#> `old$y`: 1 2 5
#> `new$y`: 1 7 2
compare() 第一个参数是旧数据,第二个参数设置为新数据,比较结果清楚地展示了如何通过旧数据得到新数据。可以看到这个比较是按行进行的,也就是说每一行数据的位置对比较结果会有影响。
如果不考虑每行数据的顺序。上例中,我们其实只需要改动一行数据即可从旧数据得到新数据(把 df1 的第三行换成 df2 的第二行),我们可以通过先对两个数据框按照关键字段为索引进行排序然后再比较:
# 排序后再比较
compare(
df1[order(df1$x), ],
df2[order(df2$x), ]
)
#> `attr(old, 'row.names')`: 1 2 3
#> `attr(new, 'row.names')`: 1 3 2
#>
#> old vs new
#> x y
#> old[1, ] a 1
#> old[2, ] b 2
#> - old[3, ] c 5
#> + new[3, ] d 7
#>
#> `old$x`: "a" "b" "c"
#> `new$x`: "a" "b" "d"
#>
#> `old$y`: 1 2 5
#> `new$y`: 1 2 7
比较两个数据文件
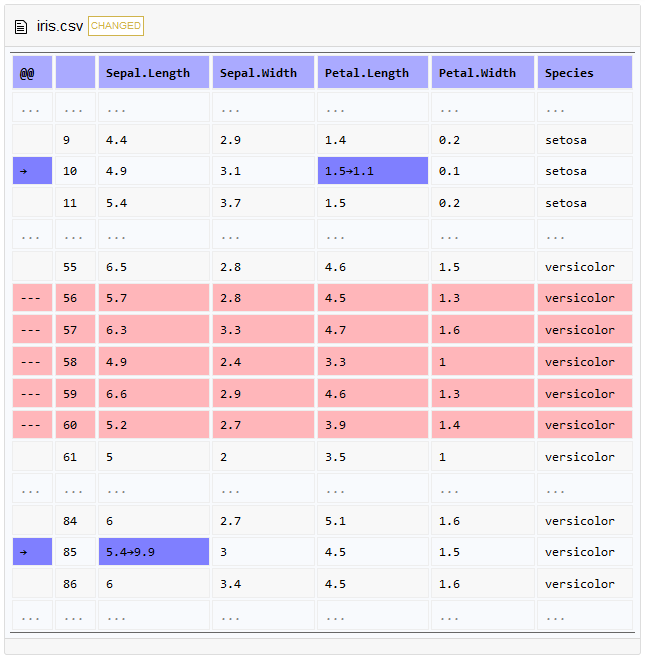
waldo 包比较的是 R 内存中的对象,而 diffviewer 包比较的是两个文件,相同的是每一行数据的位置对比较结果会有影响。diffviewer 包目前只支持 .svg、.png、.csv、.txt 四种格式,暂不支持 .xlsx 和 .xls,但可以先转化为 .csv 或者 .txt 再比较。下面以鸢尾花数据为例说明。
生成示例文件
# 加载相关 R 包
library(diffviewer)
# 对 iris 数据进行修改得到 iris2
iris2 = iris
iris2 = iris[c(1:55, 61:150), ] # 删除 5 行 数据
iris2[10, "Petal.Length"] = 1.1 # 第 10 行花瓣长度修改为 1.1
iris2[80, "Sepal.Length"] = 9.9 # 第 40 行花萼长度修改为 9.9
# iris 和 iris2 写入到 .csv 文件
write.csv(iris, "iris.csv")
write.csv(iris2, "iris2.csv")
比较两个文件的差异
visual_diff("iris.csv", "iris2.csv")