找到你最需要的最棒的 R 包
楚新元 / 2023-10-11
寻找满足需求的 R 包
比如我现在需要一个能读取 Excel 文件的 R 包,你可以用 pkgsearch 包帮你搜索一下,比如用关键词 “read excel” 来搜:
library(pkgsearch)
pkg = ps("read excel", size = 20)
DT::datatable(pkg[c(1:2, 4)])
你可以用 View(pkg) 获得更多的信息。
哪一个包最棒?
能满足需求的包可能不止一个,我该选哪一个呢?或许下载量指标是个不错的指标。需要说明的是下载量最大的包不一定就是最棒的包,因为新包由于知名度较低,可能下载量比较低,但是对于老包,这个指标还是很有代表性的。另外下载量最大的包在具体某个功能点上未必就是最好的。
我对包更挑剔点,在能满足要求的前提下,我更喜欢轻量级的包。如果是写 R 包你会发现尽量用 base R 自带的函数更好。
统计相关包的下载量
# 加载相关 R 包
library(cranlogs)
use("dplyr", c("mutate", "summarise", "slice_max"))
# 获取 RStudio CRAN mirror 下载量数据
packages = c("readxl", "xlsx", "openxlsx", "XLConnect")
data = cran_downloads(
packages = packages,
from = "2020-01-01",
to = "2025-12-31"
)
# 按照年份统计每个包的下载量
data |>
mutate(
year = format(date, "%Y")
) |>
summarise(
count = sum(count),
.by = c(year, package)
) -> total_by_year
# 按照包分组统计总下载量
data |>
summarise(
count = sum(count),
.by = package
) -> total
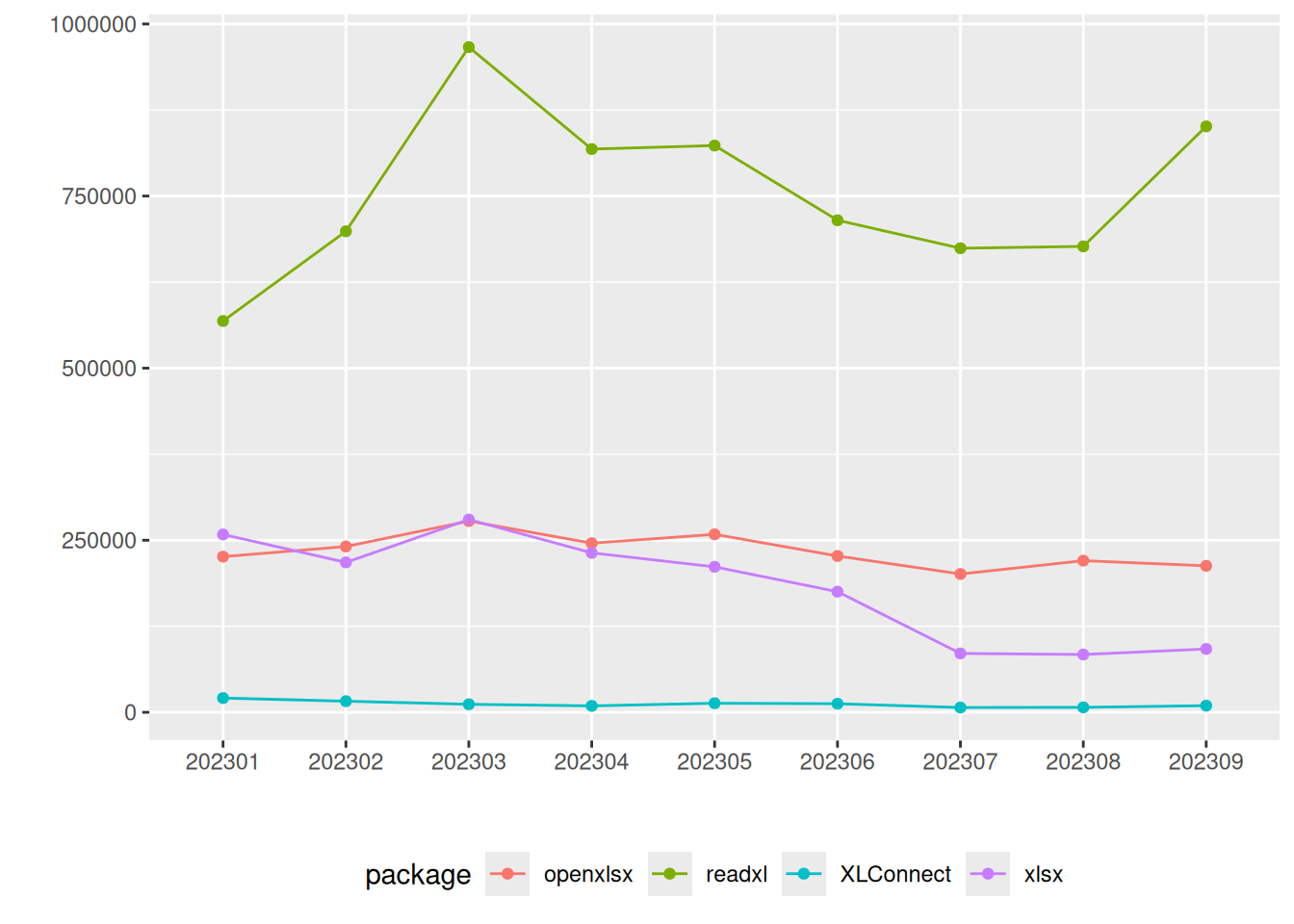
下载量走势图更直观
更新 2026-06-10
走势图此前用的是 echarts4r 生成的动态图,但是每次打开网页时间都比较长,现改为 ggplot2 生成的静态图,同时将包的下载量数据更新到 2025 年 12 月 31 日。
每年下载量
library(ggplot2)
library(scales)
total_by_year |>
ggplot() +
geom_line(
aes(x = year, y = count, color = package, group = package)
) +
# 突出数据的同时淡化其它数据
gghighlight::gghighlight(
use_direct_label = FALSE,
unhighlighted_params = list(color = alpha("grey85", 1))
) +
# 添加最后一期数据标签
geom_point(
data = total_by_year |> slice_max(year, by = package),
aes(x = year, y = count, color = package),
shape = 16
) +
geom_text(
data = total_by_year |> slice_max(year, by = package),
aes(x = year, y = count, color = package, label = count),
vjust = -1, size = 2.5, fontface = "bold"
) +
scale_color_manual(values = MetBrewer::met.brewer("Austria")) +
facet_wrap(~ package) +
coord_cartesian(clip = "off") +
scale_y_log10(
breaks = trans_breaks("log10", function(x) 10^x),
labels = trans_format("log10", math_format(10^.x))
) +
theme_minimal() +
theme(
legend.position = "none",
axis.title = element_blank(),
axis.text = element_text(
size = 12, color = "#333333"
),
strip.text = element_text(
size = 14, face = "bold", color = "#333333"
),
plot.margin = margin(10, 10, 10, 10),
plot.background = element_rect(
color = "#F4F5F1", fill = "#F4F5F1"
)
)
累计下载量
total |>
ggplot(aes(x = package, y = count, fill = package)) +
geom_bar(stat = "identity", alpha = 0.7) +
scale_fill_manual(values = MetBrewer::met.brewer("Austria")) +
scale_y_log10(
breaks = trans_breaks("log10", function(x) 10^x),
labels = trans_format("log10", math_format(10^.x))
) +
theme_minimal() +
theme(
legend.position = "none",
axis.title = element_blank(),
axis.text = element_text(
size = 12, color = "#333333"
),
strip.text = element_text(
size = 14, face = "bold", color = "#333333"
),
plot.margin = margin(10, 10, 10, 10),
plot.background = element_rect(
color = "#F4F5F1", fill = "#F4F5F1"
)
)
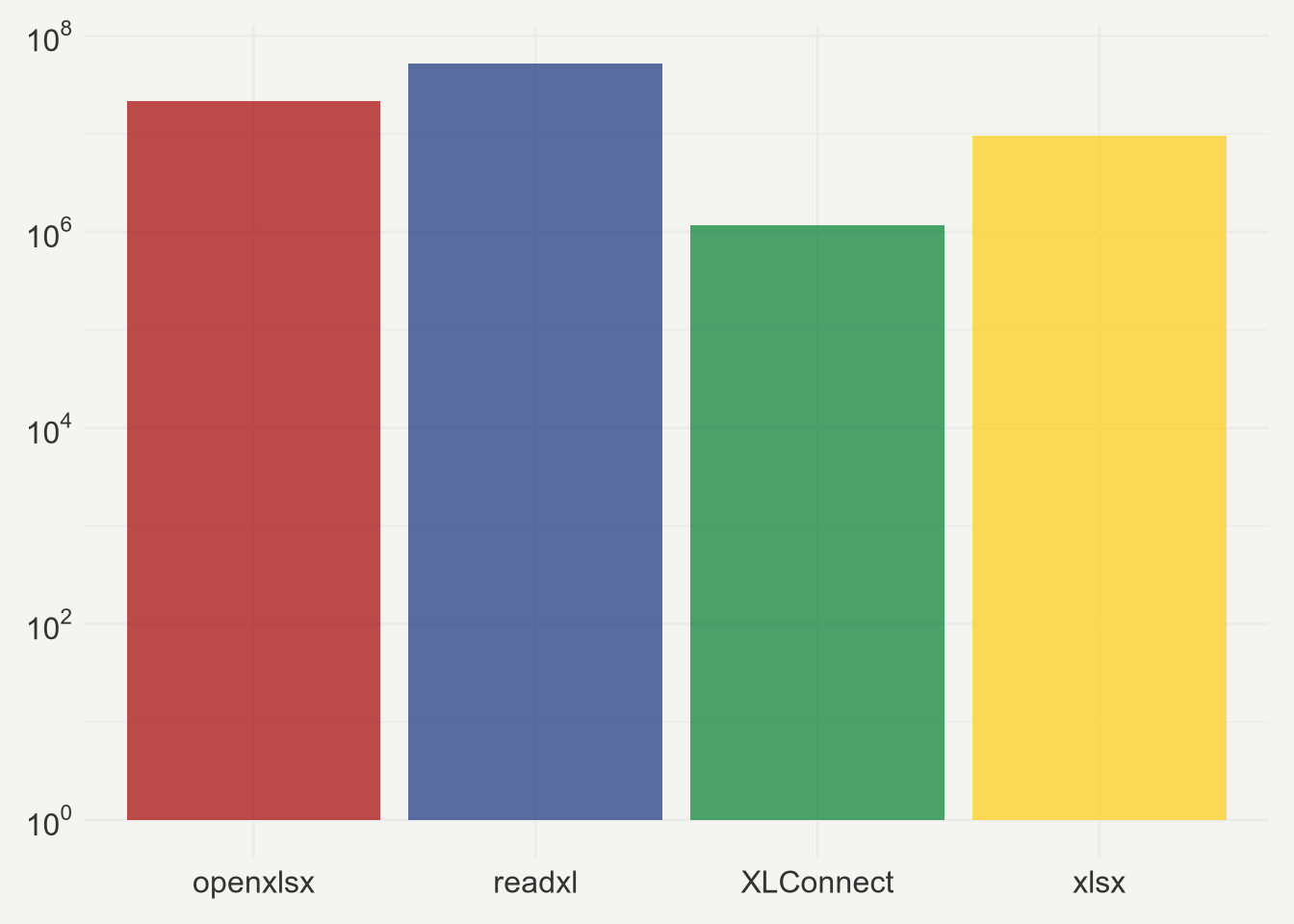
一图胜千言,不可否认:仅仅只是读取 Excel 文件,readxl 包确实是目前最棒的包,支持 .xlsx 和 .xls 两种格式,它的底层是基于 C 和 C++,读取速度也非常快。
如果除了读取外,还有其他需求,比如定制个性化的报表,那么 openxlsx 包就非常值得深入学习了。但是 openxlsx2 因为比较新,所以从下载量上看对与新包多少有点不公平,实际上我更推荐 openxlsx2 包,函数名统一用下划线而不是驼峰,功能更强大。
如果要读取复杂的 Excel 表格数据,比如通过数据透视表生成的数据1,那么 tidyxl 包就很有必要了。
知乎上张敬信老师写了一篇文章《tidyxl包:复杂Excel表格数据读取(逆透视)》供参考。 ↩︎